Ziel
Ich hätte gern so ein Alexa / Google Assistant Ding - aber eben ohne diesen ganzen "Jeder-Hört-mit" Mist. Es müsst doch auch möglich sein, das ganze irgendwie selber zu hosten und dadurch selber zu verarbeiten.
Einen aufgeborten Home-Assistant der mir alle Lichter, Jalousinen, einige Steckdosen, die Heizung und noch ein paar andere Dinge steuert, hätt ich ja schon. Es stehen auch schon einige RaspberryPis an strategisch günstigen Plätzen herum, die man doch für die Audio-Aufnahme verwenden könnte.
Also, einfach ein paar Mikrophone (ReSpeaker, 3.5mm Tischmikro und USB Soundkartenstecker) kaufen, ein bisschen herumspielen und naja - wird scho irgendwie gehn. So schwer kanns ja nicht sein.
Grundlagen
Wie funktioniert so ein Sprachassistent überhaupt? Mir persönlich war das natürlich von Anfang an ganz klar. Auch würd ich keinem Leser hier unterstellen, dieses Wissen nicht inne zu haben - dennoch, schadet es vielleicht nicht an der Stelle einige Begriffe zu klären.
Ein Vorgriff auf später: Das Programm Rhasspy bietet einen sehr schönen Überblick über die einzelnen Bereiche eines Sprachassistenten. Aus Mangelung eines besseren Beispiels werde ich mich einfach an diese Aufteilung halten.
Also:
- der Sprachassistent beginnt gewissermaßen mit einem Audio-Input - d.h. das Programm bekommt entweder über ein Mikro oder über einen Stream Audiodaten zugeschickt.
- Diese Daten werden (falls so eingestellt) nach einem Wake-Word durchsucht. Also ein Wort oder eine Phrase wie zbsp. "OK Google" oder "Alexa" die dem Programm anzeigen, dass man etwas von Ihm will.
- Wenn ein Wake-Word gefunden wurde, startet ein neuer Dialog. Dieser bildet quasi eine Session oder so zu sagen ein Gespräch ab und kann auch mehrere Sätze zusammen halten.
- Der Audio-Input wird auch nach dem Wake-Word aufgezeichnet - nun startet die ASR (die Automatische Sprach eRkennung - https://www.awesomeaariv.com/asr-nlu-and-tts/03/17/2019/) und der Input wird an die nächste Stelle weitergegeben: An Speech-to-Text (STT). Dieser Dienst macht aus gesprochener Sprach eben lesbaren Text.
- Dann geht alles sehr schnell - eigentlich geht das überhaupt alles sehr schnell, wenn man bedenkt, was da hier sonst noch passiert. Der Text wird nach bestimmten Mustern analysiert. Dies geschieht optional mit NLU (Natürlichem Sprach Verständnis.. LU) oder einfach durch einen Abgleich von vordefinierten Sätzen und Variablen. Im Beispiel hier wird dies auch Intent Recognition genannt. Es wird also versucht zu verstehen, was der Benutzer durch den Satz erreichen will.
- Mit dem so gewonnen Intent wird über den Dialog geprüft, ob alle notwendigen Teile dieser Intention vorhanden sind. Bspw. sagt ein Benutzer nur "Licht im Wohnzimmer" könnte noch der Ziel-Zustand "an" oder "aus" fehlen. Ein optionales Dialog-Management kann fehlende Teile erfragen.
- Ist der Intent vollständig, wird er ans Intent Handling weitergegeben. An der Stelle wird dann aus der Intention eine Handlung gemacht. Im Falle von Home-Assistant, wird das Licht im Wohnzimmer ein- oder ausgeschaltet.
- Das Ergebnis vom Intent Handling ist meist eine Antwort in Textform. Bspw. "Das Licht im Wohnzimmer ist nun aus". Damit das Gespräch nicht eintönig wird, wird der Text mit Text-to-Speech (TTS) wieder in Sprache also eine .wav Datei umgewandelt.
- Diese wird dann zbsp über einen Lautsprecher ausgegeben - mit dem Audio Output endet der ganz Prozess
Jetzt wo ich mir das Bild genauer ansehe, merke ich, dass die Nummer überhaupt nicht zusammenpassen .. aber naja. Das Bild is schön und bleibt jetzt hier.
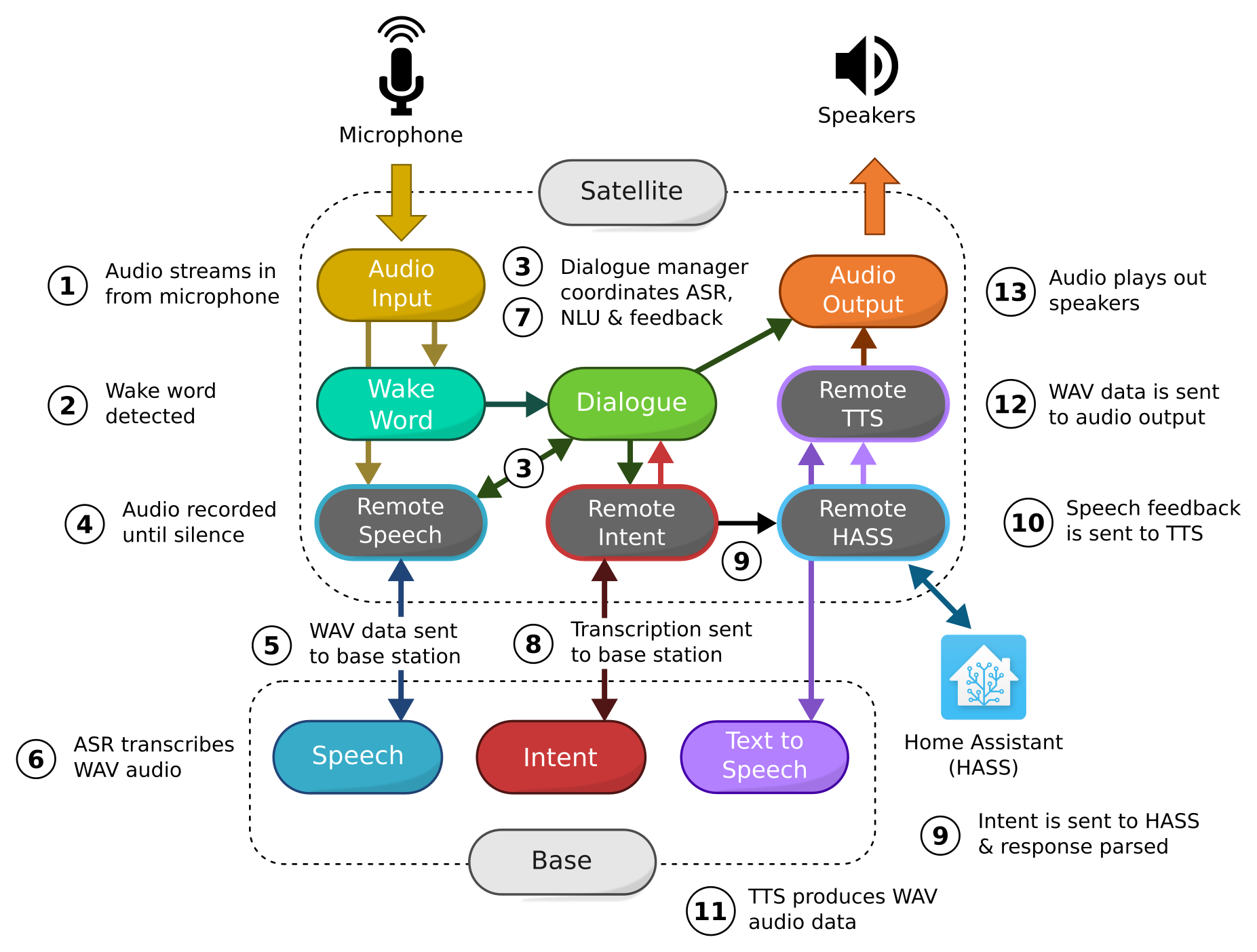
Was im Bild bereits angedeutet wird, ist, dass man die einzelnen Aufgaben auf mehrere Geräte aufteilen kann. Also einen (in diesem Beispiel) so genannten Satellit der nur für die Audio Ein- und Ausgabe zuständig ist und eine Basis, die die Verarbeitung und Umwandlung übernimmt.
Der Weg
Für HA gibt es Almond - angeblich kann das alles. Habs aber irgendwie nicht zum Laufen gebracht. Updates gibts dort eher selten und ich denke die deutsche Sprachuntersützung wird auch noch etwas länger auf sich warten lassen.
Snips war angeblich sehr cool und hat für viele sehr gut funktioniert. Allerdings hat Sonos das Unternehmen gekauft und danach einfach die Entwicklung und einen notwendigen Einsprungspunkt fürs Anlernen neuer Intents eingestellt.
HA bietet noch einige Integrationen für TTS, STT und Dialog Management - die meisten nutzen aber wieder nur externe Dienste (dialogflow nutzt Google, Alexa schickt zu Amazon, Watson zu IBM, und von Microsoft gibts auch noch was).
Ich hab mich nun mit Rhasspy etwas - länger als gedacht - auseinandergesetzt und glaube, damit alles notwendige abgedeckt zu haben.
Lösung
Ein einfaches Beispiel wäre die Installation von Rhasspy auf einem Raspberry mit raspbian -da würde alles schön einfach laufen. Man bräuchte keine umständliche Konfiguration zwischen mehreren Geräten oder unterschiedlichen Systemen, man müsste sich nicht mit MQTT auseinander setzen und schon alleine das Testen wäre einfacher - kurz gesagt, ziemlich langweilig und es gibt schon genügend Anleitungen davon im Netz.
In diesem Setup wird die Arbeit aufgeteilt.
Die Basis (Base) ist zuständig für:
- STT
- Intent Recognition
- TTS
- Intent Handling
- Dialog Management
Die Satelliten sind zuständig für:
- Audio Input
- Wake-Word Erkennung
- Audio Output
Das Intent-Handling wird in diesem Setup an eine Home-Assistant Installation weitergereicht. Notwendige Einstellungen dafür finden sich noch weiter unten. Möglich wären hier auch andere Installationen wie zbsp. Node-Red.
Aufnahme auf RPI vorbereiten
Unter Umständen kann diese Punkt ausgelassen werden. Sollten jedoch Probleme bei der Aufnahme vorkommen (zbsp.: rhasspy hört nix), können folgende Punkte helfen:
asound.conf einrichten
$ aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: sndrpihifiberry [snd_rpi_hifiberry_dacplus], device 0: HiFiBerry DAC+ HiFi pcm512x-hifi-0 [HiFiBerry DAC+ HiFi pcm512x-hifi-0]
Subdevices: 1/1
Subdevice #0: subdevice #0
$ arecord -l
**** List of CAPTURE Hardware Devices ****
card 5: MIC [USB MIC], device 0: USB Audio [USB Audio]
Subdevices: 0/1
Subdevice #0: subdevice #0
Werte können natürlich abweichen je nachdem welche Hardware verwendet wird. So können hier auch mehrere Geräte aufgelistet werden. Wichtig hier ist jedenfalls nur, dass die Wiedergabe auf 0,0 und die Aufnahme auf 5,0 laufen soll.
in der /etc/asound.conf schaut das dann so aus:
pcm.softvolume {
type plug
slave.pcm "softvol"
}
pcm.softvol {
type softvol
slave {
pcm "plughw:5,0"
}
control {
name "SoftMaster"
card 5
device 0
}
max_dB 0.0
min_dB -50.0
resolution 100
}
pcm.!default {
type asym
capture.pcm "mic"
playback.pcm "speaker"
}
# ab hier kommen die Änderungen hinzu
pcm.mic {
type plug
slave {
pcm "hw:5,0"
}
}
pcm.speaker {
type plug
slave {
pcm "hw:0,0"
}
}
(Bei Änderung der Datei empfiehlt es sich den Docker Container neuzustarten)
Lautstärke des Mikrophons erhöhen
Eventuell ist auch einfach die Lautstärke des Mikros zu gering - das kann durch den alsamixer gefixt werden:
alsamixer
# F6 - richtiges device auswählen
# F4 - auf Aufnahme stelleen
# den gain erhöhen - je nach Gerät
# einstellungen in /var/lib/alsa/asound.state für den nächsten Neustart speichern
sudo alsactl store
# oder in eine andere datei
# alsactl --file ~/.config/asound.state store
(Änderungen hiermit sollten direkt im laufenden Betrieb ersichtlicht sein.)
docker installieren
Rhasspy gibts als Docker image:
https://hub.docker.com/r/rhasspy/rhasspy
Auf den meisten Satelliten läuft bei mir Volumio (https://volumio.org/). Eine Art Jukebox mit Web Oberfläche. Die Distribution basiert hier auf einem Debian. Zusätzlich steht im Wohnzimmer noch ein Raspi mit Kodi zum Film abspielen. Dort läuft ein Libreelec, dass deutlich eingeschränkter mit der Installation neuer Software umgeht.
Je nach Betriebssystem wird Docker unterschiedlich installiert. Am besten einfach im Internet suchen, falls hier jemand eine andere Distribution verwendet.
Für Volumio (Standard Docker Installation):
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker volumio
sudo pip3 install docker-compose
Für Kodi (über Docker Addon):
Über ein eigenes Addon-Repository (TODO: Anleitung suchen)
docker-compose installieren:
binary suchen
Die Base läuft auf einem etwas stärkeren Synology NAS.
- Docker über Synology Pakage Manager installiern
- docker compose installieren

docker starten
Den Rhasspy Service startet man am besten über eine docker-compose.yml Datei:
version: "3"
services:
rhasspy:
image: "rhasspy/rhasspy"
container_name: rhasspy
restart: unless-stopped
volumes:
- "./config:/profiles"
- "/etc/localtime:/etc/localtime:ro"
ports:
- 12101:12101
# MQTT Broker - see: https://rhasspy.readthedocs.io/en/latest/installation/
- 12183:12183
# in meinem Fall gibts am server keinen sound
# devices:
# - "/dev/snd:/dev/snd"
command: --user-profiles /profiles --profile de
sysctls:
- net.ipv6.conf.all.disable_ipv6=1
marytts:
image: synesthesiam/marytts:5.2
container_name: marytts
# dieses verzeichnis muss erst richtig vorbereitet werden
volumes:
- "./marytts-config/lib:/marytts/lib"
ports:
- 59125:59125
restart: unless-stopped
tty: true
sysctls:
- net.ipv6.conf.all.disable_ipv6=1
docker-compose.yml Datei für Satelliten.
version: "3"
services:
rhasspy:
image: "rhasspy/rhasspy"
container_name: rhasspy
restart: unless-stopped
ipc: host
volumes:
- "./config:/profiles"
- "/etc/localtime:/etc/localtime:ro"
- "/etc/asound.conf:/etc/asound.conf:ro"
ports:
- 12101:12101
devices:
- "/dev/snd:/dev/snd"
command: --user-profiles /profiles --profile de
die wichtigsten docker-compose Befehle:
# starten
docker-compose up -d
# stoppen
docker-compose down
# updaten
docker-compose pull
docker-compose up -d
RaspberryPi zero
Falls jemand das ganze erfolglos auf dem raspberry pi zero (rpi0) versucht - auch hier lohnt sich das lesen des verfluchten manuals (RTFM):
https://rhasspy.readthedocs.io/en/latest/installation/
sudo sh -c 'echo { \"experimental\": true } > /etc/docker/daemon.json'
sudo systemctl restart docker
docker pull --platform linux/arm/v6 rhasspy/rhasspy
Für den rpi0 hab ich kein docker-compose binary gefunden - in dem Fall kann man den Container auch so starten:
docker run -d -p 12101:12101 \
--name rhasspy \
--restart unless-stopped \
-v "${PWD}/config:/profiles" \
-v "/etc/localtime:/etc/localtime:ro" \
-v "/etc/asound.conf:/etc/asound.conf:ro" \
--device /dev/snd:/dev/snd \
--ipc host \
rhasspy/rhasspy \
--user-profiles /profiles \
--profile de
ACHTUNG: Einfach starten ist nicht - geht nicht. Die verlinkten Verzeichnisse (config und marytts-config am Server) müssen erst erzeugt bzw. vorbereitet werden.
Also sucht euch zuerst einen Ort an dem Ihr diese Verzeichnisse erstellt bzw. docker-compose.yml Dateien ablegt . Beachtet dabei, dass diese Verzeichnisse alle Einstellungen enthalten - wäre also gut, wenn diese leicht zu sichern sind. Außerdem beachtet, dass die rhasspy Konfiguration (je nach eingesetzten Systemen) schnell mehrere hundert Megabyte ausmacht. Die MaryTTS Sprach-Modelle schlagen unter Umständen auch gleich mit mehr als einem Gigabyte zu.
mkdir config
mkdir marytts-config # am server
marty-tts vorbereiten
Der marty-tts Container kommt bereits mit einigen Sprachen vorinstalliert. Für Deutsch gibt es noch ein etwas weniger nach Computer klingendes Sprachmodell.
# TODO - gzunip befehl hinzufügen
wget 'https://github.com/marytts/voice-dfki-pavoque-styles/releases/download/v5.2/voice-dfki-pavoque-styles-5.2.zip'
wget 'https://github.com/marytts/voice-dfki-pavoque-neutral-hsmm/releases/download/v5.2/voice-dfki-pavoque-neutral-hsmm-5.2.zip'
wget 'https://github.com/marytts/voice-dfki-pavoque-neutral/releases/download/v5.2/voice-dfki-pavoque-neutral-5.2.zip'
wget 'https://github.com/marytts/marytts/releases/download/v5.2/marytts-5.2.zip'
Wer auf das vorerst verzichten will, kann das Volume beim marytts container einfach mal weglassen.
Daran hängen einfach ein Paar Lautsprecher (teilweise über USB, USB Soundkarten+Klinke oder über HATs wbsp. hifiberry/phat dac). Für den Sprach Assistanten sind nun noch verschiedene Mikrophone im Einsatz (Klinke, USB oder ein ReSpeaker Array).
Damit wärn die groben Sachen mal vorbereitet. Nun gehts weiter mit Rhasspy und Home-Assistant.
Rhasspy konfigurieren

und an einem Satelliten:

(TODO: am Satellite sollte natürlich arecord bei der Mikrophon Einstellung stehen. Hermes macht dort keinen Sinn.(
Inzwischen bin ich auf "nicht mehr ganz offline" umgestiegen - da die Sprachausgabe von Google's WaveNet doch deutlich besser ist, als die Alternativen.
Wichtig bei de Einstellungen: ich verwende MQTT um Nachrichten zwischen den Systemen auszutauschen. Als MQTT Server dient die Basis selbst - daher wird der port 12183 im Basis Docker Container freigegeben. Bei den Satelliten wird einfach die IP der Basis + dieser Port angegeben und schon kann bei den restlichen Systemen "Hermes" als Protokoll angegeben werden.
In den Feldern mit dem Namen Satellite siteIds in der Basis gehören alle Namen der Rhasspy Satelliten und ein Eintrag für den homeassistant selbst, mit Beistrich getrennt. Warum wird später erklärt.
in der sentences.ini werden die zu erkennenden Sätze hinterlegt und sogenannte slots ausgewertet:
; in eckiger Klammer stehen die intents
; darunter alle sätze die diesen auslösen können
; es gibt [optional] (alter|nativen) und [(optionale|alternativen)]
; mit XX= kann man sich alternativen/listen in variablen schreiben
; und später mit <XX> darauf zugreifen
; mit {parameter:fixer wert} können werte an den Intent übergeben werden
; und mit ($slotname) greift man auf die optionen in den slots zu
;
[GetTime]
wie spät ist es [(jetzt|momentan|gerade|aktuell|eigentlich)]
[Entities]
; slots für lichter, schalter
; was geht hier ab?
; in <light_names> stehen danach alle lichter namen
; findet das intent recognition dann einen passenden satz wo dieser licht name vorkommt
; wird dieser name in die variable {entity_name} geschrieben, und zusammen mit den anderen parametern
; an den intent handler weiter gegeben
light_names = ($light_names){entity_name} (:){domain:light} (:){domain_name:Licht} (:){domain_article:das}
switch_names = ($switch_names){entity_name} (:){domain:switch} (:){domain_name:Schalter} (:){domain_article:der}
; slot für stock werke
areas = ($areas) {area}
; slot für schalter aktionen
switch_actions = ($switch_actions)
[SwitchControl]
; dreh das licht im büro unten um
; dreh das büro licht unten um
; dreh im büro unten das licht um
(dreh|drah|schalte|schalt) [bitte] ((das|des) Licht (im|beim|vom|in der) <Entities.light_names> [<Entities.areas>]|(das|des) <Entities.light_names> Licht [<Entities.areas>]|(im|beim|vom|in der) <Entities.light_names> [<Entities.areas>] (das|des) Licht|den Schalter (im|beim|vom|in der) <Entities.switch_names> [<Entities.areas>]|den <Entities.switch_names> Schalter [<Entities.areas>]|(im|beim|vom|in der) <Entities.switch_names> [<Entities.areas>] den Schalter) <Entities.switch_actions>
Die Slots werden in eigenen Dateien im slots abgelegt:
; Datei: slots/areas
(Draußen:im Aussenbereich):Aussenbereich
(ganz unten|im Keller|im Untergeschoss):Untergeschoss
(ganz oben|am Dach):Dach
(oben|im Ersten Stock|im Obergeschoß):(Erster Stock)
(unten|im Erdgeschoß):Erdgeschoss
; Datei: slots/switch_actions
(ein|auf|an):(ein) (:){action:turn_on} (:){action_name:ein}
(aus|ab|ob):(aus) (:){action:turn_off} (:){action_name:aus}
um (:){action:toggle} (:){action_name:um}
; Datei: slots/light_names
Wohnzimmer
Terrasse
(Bad|Badezimmer):(Bad)
(Wc|Klo):WC
Büro
Garage
(Bad Dusche|Dusche|Bad hinten):(Bad Dusche)
Dachboden
Garderobe
Schlafzimmer
Küche
Esstisch
(Flur|Vorraum|Gang):(Flur)
; Datei: slots/switch_names
Steckdose Drucker
Steckdose Media Player
Steckdose Fernseher
Bad Heizkörper
(Christbaum|Christbaum Steckdose|Weihnachtsbaum):(Christbaum Schalter)
Mit diesen Dateien und Einstellungen kann man schon das mal versuchen den Intent-Recognizer zu trainieren - dazu rechts oben einfach auf "train" klicken und warten.
Abhängig von der CPU und der Anzahl der Sätze kann dies zwischen 10 Sekunden und 5 Minuten dauern.
Jetzt fragt man sich: Muss das wirklich so kompliziert sein? Nein - es ginge auch viel einfacher - dann wärs aber nicht so genial - und niemand würde was dabei lernen..
und ja - ich habs schon vereinfacht..
Home-Assistant konfigurieren
Ich setze jetzt einfach mal voraus, dass schon ein home-assistant ohne Probleme läuft und wir nur noch die Sprach-Erkennung einrichten müssen.
Durch einen Klick auf euer Bild im links unten - kommt ihr zu den Einstellungen um ein "Langlebiges Zugangs-Token" zu erstellen - dieses tragt ihr noch bei der Basis zusammen mit der Option "send intents" unter Intent Handling ein.
In der configuration.yaml passieren nun einige wirklich geniale Sachen - wenn ich mal Zeit hab, erklär ichs vielleicht...
# wir verbinden uns zum MQTT server der Rhasspy Basis
mqtt:
broker: base
port: 12183
# generelles intent handling aktivieren
intent:
# ich lege hier mal zwei intents also zwei "absichten" an
intent_script:
# hier einen ganz einfachen - der die Zeit zurück gibt
GetTime:
speech:
text: Es ist jetzt {{ as_timestamp (now()) | timestamp_custom('%H') }} Uhr {{ as_timestamp (now()) | timestamp_custom('%M') | regex_replace('^0+', '') }}
# und dann den "Alles schalter"
# abhängig von den übergebenen Werten kann der
# alles ein/aus/um schalten
SwitchControl:
speech:
text: '{{ domain_article }} {{ entity_name }} {{ domain_name }} {{ area }} wird nun {{ action_name }}geschaltet.'
async_action: true
action:
- service: 'script.assistant_find_entity'
data:
domain: '{{ domain }}'
domain_name: '{{ domain_name }}'
action: '{{ domain }}.{{ action }}'
action_name: '{{ action_name }}'
entity_name: '{{ entity_name }}'
area: '{{ area }}'
# der hier wird nur als durchschleifer benutzt
# er nimmt den übergebenen satz, publiziert ihn über MQTT
# und lässt rhasspy die auswertung machen.
# Als Absender (siteId) wird der Name "assistant" gewählt
# dadurch agiert der home-assistant als eigener Satellit.
# dies soll verhindern, dass andere Satelliten die Antwort bekommen.
AskRhasspy:
speech:
text: >-
{%- if state_attr('sensor.assistent_nachricht_ok', 'text') and states.sensor.assistent_nachricht_ok.last_updated > states.sensor.assistent_nachricht_nicht_verstanden.last_updated -%}
OK {{ state_attr('sensor.assistent_nachricht_ok', 'text') }}
{%- elif state_attr('sensor.assistent_nachricht_nicht_verstanden', 'input') and states.sensor.assistent_nachricht_ok.last_updated < states.sensor.assistent_nachricht_nicht_verstanden.last_updated -%}
NOK Das habe ich nicht verstanden
{%- endif %}
async_action: false
action:
- service: 'mqtt.publish'
data:
topic: hermes/nlu/query
payload_template: '{"input": "{{ question }}", "siteId": "assistant"}'
- wait_template: ''
timeout: '0:00:03'
# das conversations wird benutzt um direkt mit dem HA chatten zu können
# siehe Mikrophon Knopf oben rechts
conversation:
# normalerweise müssten wir hier alle erlaubten Sätze nochmal eingeben
# aber wir sind faul und schicken einfach alles zum Rhasspy durchschleifer
AskRhasspy:
- '{question}'
# hangouts bzw. auch andere chatbots erlauben das entgegennehmen von intents
hangouts:
intents:
# auch hier nur unser durchschleifer..
AskRhasspy:
sentences:
- '{question}'
conversations:
- id: !secret hangout_andreas
# da meine lichter/schalter namen, oft unterschiedlich zu den entity-Ids der lichter sind,
# benötigt es hier ein etwas umständliches matching.
# im grunde wird nach entites mit dem entsprechenden namen gesucht
# und die entity-ids werden ans nächste script weiter gegeben.
script:
assistant_find_entity:
alias: Assistent - Entity finden
icon: mdi:auto-fix
sequence:
- service: script.assistant_execute_service
data_template:
service_name: "
{%- if action != '' -%}
{{ action }}
{%- else -%}
{%- set entity_name = script_name | trim -%}
{%- for entity in states['script'] -%}
{%- set entity_id_parts = entity.entity_id.split('.') -%}
{%- set friendlyname = entity.attributes.friendly_name -%}
{%- set friendlyname = friendlyname | regex_replace(find='- |: ', replace='', ignorecase=True) | trim -%}
{%- if friendlyname | regex_search(find=entity_name, ignorecase=True) != 0 -%}
{{ entity.entity_id }}
{%- endif -%}
{%- endfor -%}
{%- endif -%}"
entity_id: "
{%- set entity_name = entity_name | trim -%}
{%- for entity in states[domain] -%}
{%- set entity_id_parts = entity.entity_id.split('.') -%}
{%- set friendlyname = entity.attributes.friendly_name -%}
{%- set friendlyname = friendlyname | regex_replace(find='Licht|Dimmer', replace='', ignorecase=True) | trim -%}
{%- set friendlyname = friendlyname | regex_replace(find='- |: ', replace='', ignorecase=True) | trim -%}
{%- set friendlyname = friendlyname | regex_replace(find='[0-9]+$', replace='', ignorecase=True) | trim -%}
{%- if area == '' -%}
{%- set friendlyname = friendlyname | regex_replace(find='Aussenbereich|Erdgeschoss|Erster Stock|Untergeschoss|Dach', replace='', ignorecase=True) | trim -%}
{%- else -%}
{%- set area = area + ' ' -%}
{%- endif -%}
{%- if friendlyname | regex_search(find='^'+area+entity_name+'$', ignorecase=True) != 0 -%}
{{- entity.entity_id -}},
{%- endif -%}
{%- endfor -%}"
mode: single
assistant_execute_service:
alias: Assistent - Dienst Ausführen
icon: mdi:auto-fix
sequence:
- service: "{{ service_name | regex_replace(find=',$', replace='', ignorecase=True) | trim }}"
data_template:
entity_id: "{{ entity_id | regex_replace(find=',$', replace='', ignorecase=True) }}"
mode: parallel
max: 10
# jetzt fehlt nur noch eines, damit die ganze sache rund läuft.
# denn wir können über den hangouts bot mit dem Home-Assistant kommunizieren
# in dem wir die nachricht direkt weiter an rhasspy schicken.
# Die Antwort bleibt allerdings einfach am MQTT broker hängen.
# daher greifen wir uns diese nachrichten erstmal in einem sensor ab
# ausgelesen wird diese dann im intent > speech - daher dort die verzögerung um 3 sekundn.
sensor:
# wenn alles gut geht
- platform: mqtt
# sensor.assistent_nachricht_ok
name: 'Assistent Nachricht ok'
state_topic: 'hermes/tts/say'
value_template: >
{% if value_json is defined and value_json.siteId == 'assistant' %}
{{ value_json.text }}
{% else %}
{{ '' }}
{% endif %}
json_attributes_topic: 'hermes/tts/say'
expire_after: 60
icon: mdi:clippy
# aber auch wenn der text nicht erkannt wurde.
- platform: mqtt
# sensor.assistent_nachricht_nicht_verstanden
name: 'Assistent Nachricht nicht verstanden'
state_topic: 'hermes/nlu/intentNotRecognized'
value_template: >
{% if value_json is defined and value_json.siteId == 'assistant' %}
{{ 'Das habe ich nicht verstanden' }}
{% else %}
{{ '' }}
{% endif %}
json_attributes_topic: 'hermes/nlu/intentNotRecognized'
expire_after: 60
icon: mdi:clippy
Nun sollte es möglich sein, sowohl über
- den rhasspy Sprach Assistenten
- den Hangouts Chatbot und
- dem Conversations Plugin im HA mit dem Satz:
Schalte das Licht in der Küche um
Das Licht in der Küche umzuschalten.
(also - zumindest falls es einen Küchen-Licht-Schalter im HA dafür gibt..)
!!!woop woop!!!
SO - how is it going?
hahahah
(starting and ending with green)
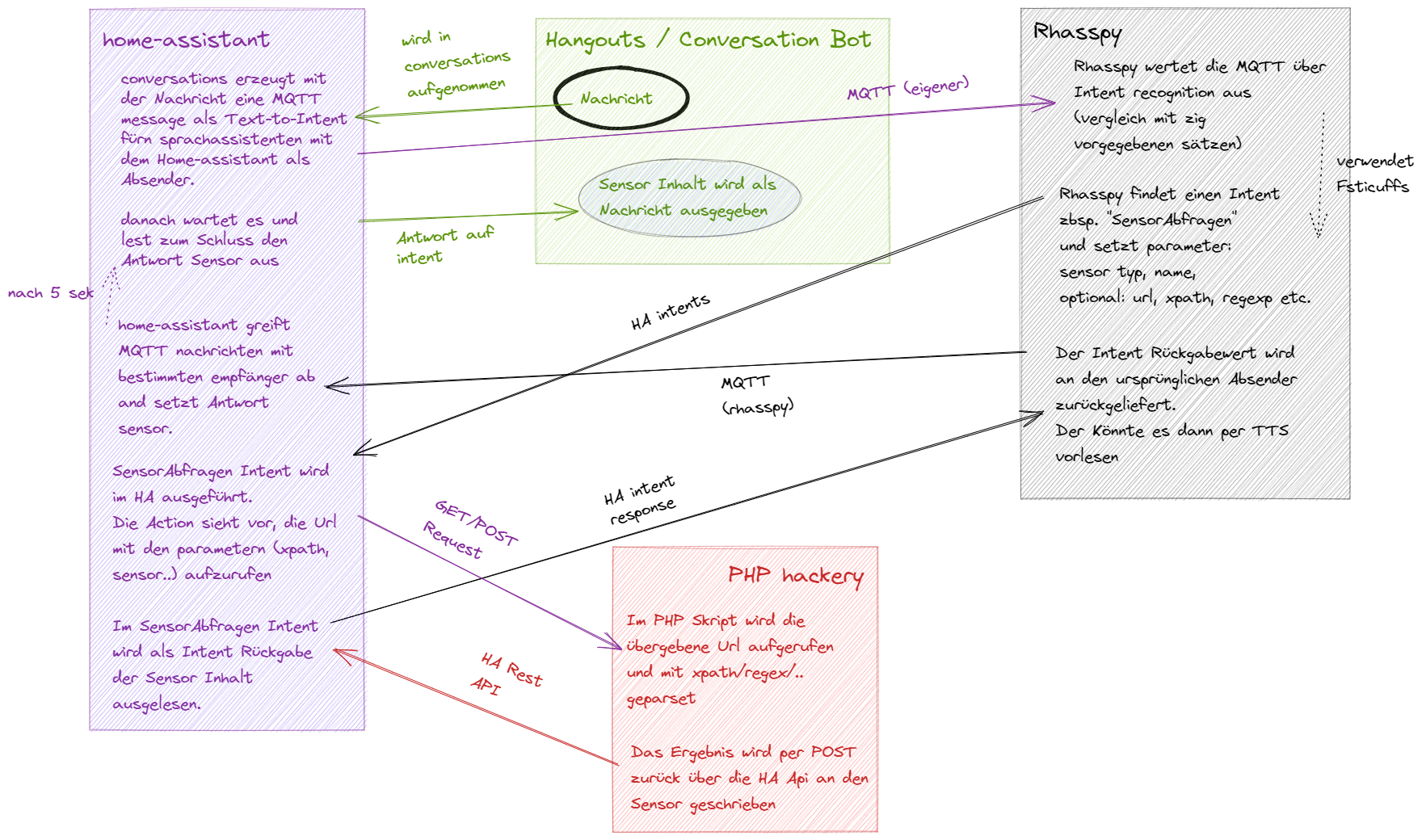
WIP
test-script mit arecord und a play
lautstärke mit alsamixer
home-assistant script und intents herrichten
ein wort zur hardware
Plan für später
Derzeit ist noch alles auf statischen Methoden aufgebaut. Für TTS, STT und Intent Handling gebe aus auch dynamische Alternativen die verschiedene Möglichkeiten der künstlicher Intelligenz verwenden. Für TTS wäre das Mozilla-TTS oder Larynx. Für STT gibts das mycroft und für Intent Handling existiert RasaNLU. Angeblich alles super toll - setzt aber in den meisten Fällen auf TensorFlow oder pytorch und diese wiederum benötigen gewisse CPU Features (AVX), GPUs oder dezidierte TPUs. Da dies mein kleiner Home-Server jedoch nicht hat, mach ich fürs erste einen großen Bogen um dieses Teilgebiet.